
北京时间2月16日凌晨,OpenAI正式发布了视频生成模型Sora,逼真的视频效果刷新了人们对AI能力边界的认知,让「一句话生成视频」的前沿AI技术不断向前迈进。
从文字(ChatGPT)到图片(DALL·E )再到视频(Sora),OpenAI的突破再次引发了业界对于生成式AI技术方向的大讨论。
Sora官网地址:https://openai.com/sora
据介绍,Sora能根据文字指令创造出既逼真又充满想象力的场景,生成长达1分钟的高清视频。所制作出的复杂场景,不仅可以包括多个角色,还有特定的动作类型,以及对人物和背景的精确细节描绘。
Sora横空出世后,OpenAI很快公布了技术报告。

技术报告地址:https://openai.com/research/video-generation-models-as-world-simulators
在技术报告中,OpenAI重点展示了(1)将所有类型的视觉数据转化为统一表示,从而能够训练生成模型的方法;(2)对Sora的能力和局限性进行定性评估。
技术介绍
OpenAI探索了视频数据生成模型的大规模训练。具体来说,研究人员在可变持续时间、分辨率和宽高比的视频和图像上联合训练了一个文本条件扩散模型。
先前,Runway、Pika等发布的文生视频产品通常只关注一小类视觉数据、较短或固定大小的视频。而Sora是视觉数据的通用模型,可以生成不同时长、长宽比和分辨率的视频和图像,而且最多可以输出长达1分钟的高清视频。
在数据方面,与以往文生视频模型相比,Sora有了重大突破。
OpenAI将视频和图像表示为patch,类似于GPT中的token。
OpenAl受到大型语言模型通用训练的影响,将所有类型的视觉数据转化为统一表示patches,这也是Sora的核心。
patches是训练生成各种类型视频和图像模型的可扩展表示,带有时间和空间信息,还可以自由排列,灵活度极高,可以用于训练不同类型的视频和图像的生成模型。
在更高层面上,研究者首先将视频压缩到较低维的潜在空间,然后分解为时空 patches,从而将视频转换为patches。从像素到潜在空间的编码步骤不仅发生在空间维度上(即压缩每帧的宽度和高度),也发生在时间维度上(即压缩连续帧之间的信息)。
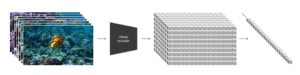
从像素到潜在表示空间的映射示意图
通过这种统一的数据表示方式,可以在比以前更广泛的视觉数据上训练模型,实现涵盖不同的持续时间、分辨率和纵横比。
与GPT类似,Sora使用transformer架构,实现卓越扩展性能。
Diffusion Transformer(DiT)技术来源于Sora研发负责人之一 Bill Peebles 与纽约大学助理教授谢赛宁撰写的论文《Scalable Diffusion Models with Transformers》。

DiT论文地址:https://arxiv.org/abs/2212.09748
研究者将「扩散 Transformer」用于视频生成,它生成的视频一开始看起来像静态噪音,通过多个步骤去除噪音,逐步转换成视频。这使得Sora可以一次性生成整个视频,也可以扩展生成的视频,使其更长。
实现功能
OpenAI声称,如果给定一段简短或详细的描述或一张静态图片,Sora就能生成类似电影的1080p场景,其中包含多个角色、不同类型的动作和背景细节。不仅如此,Sora也支持生成图像,支持将现有的静态图像生成视频,能对现有视频进行扩展以及将两个视频进行衔接并填充缺失的帧。
继Runway、Pika、Stability AI、谷歌和 Meta之后,OpenAI再次打开了文生视频的新格局。
为图像制作视频
只要输入图像和提示,Sora就能生成视频。以下视频均来源于官方技术报告:
prompt:Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
prompt:In an ornate, historical hall, a massive tidal wave peaks and begins to crash. Two surfers, seizing the moment, skillfully navigate the face of the wave.
视频内容拓展
Sora还能在开头或结尾扩展视频内容。生成视频的开头各不相同,但拥有相同的结尾。
视频编辑
扩散模型激发了多种根据文本prompt编辑图像和视频的方法。OpenAI的研究团队将其中一种方法(SDEdit)应用于Sora,使得Sora能够在零样本条件下改变输入视频的风格和环境。
连接视频
图像生成能力
此外,Sora还能生成图像。OpenAI将高斯噪声patch排列在空间网格中,时间范围为一帧。该模型可生成不同大小的图像,最高分辨率可达2048×2048。

语言理解能力
要训练像Sora这样的模型,需要庞大规模的数据集。Sora建立在过去对DALL·E和GPT模型的研究之上,使用DALL·E 3的重述提示词技术,对视频及其对应的文本描述进行详尽的标注。
这使Sora能够准确地理解用户指令中所表达的需求,借助于对语言的深刻理解,把握这些元素在现实世界中的表现形式。因此,创造出的角色,能够表达更丰富的情感。
超越视频,模拟世界
Sora如此轰动,并不只是因为AI生成的视频时间更长、清晰度更高,而是OpenAI通过Sora展现出的野心。
OpenAI要做的事情,是以视频为切入口,涵盖一切影像,模拟、理解现实世界。他们正在教AI理解和模拟运动中的物理世界,目标是训练模型来帮助人们解决需要现实世界交互的问题。
这就是OpenAI称它为「世界模拟器」的原因。
他们认为,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。
在Sora文生视频的训练过程中,OpenAI引入了DALL-E3和GPT的语言理解能力,把之前积累的技术运用到视觉模型上进行训练,使Sora能够准确地按照用户提示生成高质量的视频,这也成为了OpenAI的重要优势。
目前Sora已经能生成具有多个角色、包含特定运动的复杂场景,不仅能理解用户在提示词中的要求,还了解这些物体在物理世界中的存在方式。
此外,还能在同一视频中设计出多个镜头,并依靠对语言的深入理解准确地解释提示词,在多角度的镜头切换中,保持角色和视觉风格的一致性。通过让模型一次预见多帧画面,确保被摄体即使暂时离开视线也能保持不变。
这也使Sora出现了模拟能力,能够模拟物理世界中的人、动物和环境的某些方面,构成了「世界模拟器」的基础,具体体现如下:
三维一致性
Sora可以生成动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景在三维空间中的移动是一致的。
时间上物体的连贯性
视频生成面临的一个重大挑战是在对长视频进行采样时保持时间一致性。OpenAI 发现,虽然Sora并不总是能有效地模拟短距离和长距离的依赖关系,但它在很多时候仍然能做到这一点。
例如,即使人、动物和物体被遮挡或离开画面,Sora也能保持它们的存在。同样,它还能在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观。
与世界交互
Sora有时可以模拟以简单方式影响世界状态的动作。例如,画家可以在画布上留下新的笔触,这些笔触会随着时间的推移而持续存在,或者一人在吃汉堡时并留下咬痕。
模拟数字世界
Sora还能模拟人工进程,视频游戏就是一个例子。Sora可以通过基本策略同时控制Minecraft中的玩家,同时高保真地呈现世界及其动态。只需在Sora的提示词中提及 「Minecraft」,就能激发这些功能。
总的来说,Sora为能够理解和模拟真实世界的模型奠定了基础,这将是实现AGI(通用人工智能)的一个重要里程碑。不论是效果还是理念上,都具有划时代的意义。
有关「世界模型」的讨论
在OpenAI发布的技术报告中,直接用了“Video generation models as world simulators”这样的描述,也引起了关于「世界模型」的新一波热议。未来,Sora能否真正理解物理世界,成为业界的分歧点。
Sora的作者之一Tim Brooks表示,人工智能将能够模拟物理世界,而Sora是朝着这个方向迈出的关键一步。表明了Sora还在通用世界模型的方向上努力和前进,但是目前还并没能完全达到理解物理世界的能力。
英伟达高级科学家Jim Fan对 Sora 模型,发表了一些自己的观点。他认为:Sora是一个数据驱动的物理引擎,是一个可学习的模拟器,或世界模型。


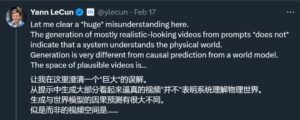
图灵奖得主Yann LeCun也表明观点。在他看来,仅仅根据prompt生成逼真视频并不能代表一个模型理解了物理世界,生成视频的过程与基于世界模型的因果预测有很大不同。
应用场景与局限
Sora在带来无限可能的同时,也将对部分行业产生巨大的影响,包括影视、广告制作、教育、游戏、新闻和动画等领域。它不仅能够在内容创造、娱乐和教育方面带来变革,还有可能改善自动化、模拟真实世界场景以及增强机器学习模型对现实世界理解的能力。
通过生成逼真的视频内容,Sora能够提供全新的交互方式和沟通手段,从而深化人类与机器之间的连接。此外,它在科研、设计、虚拟现实等领域的应用潜力也不容小觑,加速了新技术和解决方案的开发。
- 电影制作
Sora的应用在电影制作领域具有革命性意义,轻松生成吸引人电影内容的能力,预示着电影制作民主化的新时代。同时,它能够将文本脚本转化为电影风格的视频,降低了电影制作的门槛,使得个人创作者也能够制作电影内容。不仅简化了电影制作过程,还有望彻底改变电影制作领域的面貌,使其更加开放、多样化,更好地适应观众不断变化的偏好和分发渠道的发展。
- 教育
在教育领域,Sora能够将教学大纲或文本描述转化为动态视频内容,这些内容根据每个学生的独特风格和兴趣量身定制,将静态教育资源变为互动视频提供了创新方法,满足了各种学习偏好,提高学生的参与度和理解能力,为定制化教育提供了前所未有的机会。
- 游戏
传统的游戏开发往往受限于预设的环境和剧本事件。现在,利用扩散模型实时生成的动态高清视频内容和逼真音效,有望突破这些限制。Sora为游戏开发者们开辟了新天地,使他们能够创造出随玩家行为和游戏事件自然变化的游戏环境,让游戏世界变得更加生动和反应灵敏。
- 医疗保健
视频扩散模型在理解和生成复杂视频序列方面的能力,使其特别适合于识别身体内部的动态变化,如细胞早期的自我消亡、皮肤病变的发展以及不规则的人体运动。通过将Sora技术融入临床实践,不仅可以优化诊断流程,还可以根据精确的医学成像分析,为患者提供定制化的治疗方案,对于早期疾病检测和干预策略至关重要。
- 机器人
在机器人技术中,Sora可以增强机器人的视觉感知和决策能力。利用视频扩散模型创造出的高度逼真的视频序列,解决了机器人研究依赖模拟环境的局限性,为机器人提供了丰富多样的训练场景,克服了真实世界数据不足的问题,使它们能够与环境交互,并以前所未有的复杂性和精度执行任务。
谈及Sora的行业冲击时,Jim Fan评价道,Sora的物理学理解目前还是脆弱的,远非完美。它仍然会产生幻觉,生成与物理常识不符的事物,还没有很好地掌握物体交互的原理。
同时,OpenAI承认,当前的模型存在弱点。
例如,它不能准确模拟许多基本交互的物理现象,并不总是能产生物体状态的正确变化,如玻璃碎裂。
它在模拟复杂场景的物理效果上可能会遇到难题,有时也难以准确理解特定情境下的因果关系。还可能混淆提示的空间细节,例如混淆左和右,并可能难以精确描述随时间发生的事件,如跟随特定的摄像机轨迹。
此外,OpenAI尚未将Sora对公众开放,解决生成内容中的偏见问题和防止产生有害视觉内容,确保Sora输出的持续安全和无偏见是一项主要挑战。在安全性、隐私保护和内容审查等方面,Sora可能仍需进一步改进和测试。
人工智能解放了想象空间,技术的进步改变着创意表达的方式。而在技术变革过程中,保持人类的真实性和创造力仍然是十分重要的。在AI技术日益发达的背景下,真实性可能成为对抗虚构的关键,人类需要被激励成为更真实的自我。只有真正的现实,才能对抗虚幻。
作者:傅依婷
编辑: Irene


